
Memory Traces: Are Transformers Tulving Machines?
Abstract
Memory traces–changes in the memory system that result from the perception and encoding of an event–were measured in pioneering studies by Endel Tulving and Michael J. Watkins in 1975 (Tulving and Watkins, 1975). These and further experiments informed the maturation of Tulving’s memory model, from the GAPS (General Abstract Processing System) to the SPI (Serial-Parallel Independent) model (Tulving, 1983). Having current top of the line LLMs revisit the original Tulving-Watkins tests may help in assessing whether foundation models completely instantiate or not this class of psychological models.
Introduction
In the course of almost 50 years, Endel Tulving (1927-2023) developed a model of human memory, based on carefully designed experiments, culminating with the Serial-Parallel Independent model (SPI) (Endel Tulving, 1995). In this popular non-computational model, memory is composed of several hierarchically organized systems and the functional relationships between these systems drive its performance. The encoding is serial: successful coding and storage in a system depends on successful coding and storage in lower systems in the hierarchy. The retrieval from a system, in contrast, is independent of retrievals from the other systems storing the information in parallel. We designate this model and its variations and derivatives (Eustache and Desgranges, 2008) by the term Tulving Machine models.
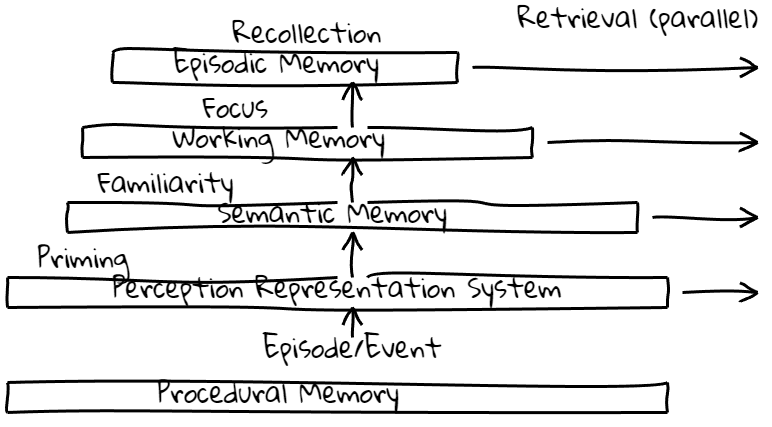
In this study, we are interested in the properties of memory traces in LLMs, compared to similar findings in human memory performance tests. More specifically, we adapt the test protocol of Tulving and Watkins (Tulving and Watkins, 1975) to operate on LLMs. Interestingly enough, the original idea informing the test, e.g. thinking of memory trace as a “cognitive blueprint” that specifies the conditions under which the recollection of an event will occur, rather than only as an after-effect of the registration of the event, seems particurlary relevant to prompt engineering in LLM operations. In both GAPS and SPI models, (a) the memory of an input event or episode is not a copy of the event, (b) the notion of a fixed trace is reconciled with the observation that its activation will depend on the retrieval environment (cue) and (c) the relation between input conditions and the trace of an item are actually observable. Namely the memory trace is defined operationally in terms of the relations between the queries directed at the system, here the LLM, and the output from the system, given a particular encoding of the event (Tulving, 1983). Using prompts both for the encoding, i.e. the registration of an event, and later retrievals, we make sure that effective retrieval cues might be quite different from the original event in a disciplined way. The test measures comparative effectiveness of various retrieval cues in producing recall.
Retrieval cueing is a prime tool for gaining information about the composition of memory traces. In the Tulving-Watkins experiment, a given trace is successively probed with two (or more) different types of retrieval cues. In the original paper, a reduction method is introduced to yield an observation of the relations among retrieval cues with respect to the trace. Central to the reduction method is Tulving’s principle of encoding specificity (Tulving, 1983): a retrieval cue is effective to the extent that its informational contents match the informational content of the trace. The quantitative measure of the effectiveness of a retrieval cue enables us to infer informational properties of a particular trace and to estimate quantitatively its constituent elements. Tulving suggests the name valence, with respect to a particular trace, for the effectiveness of a retrieval cue, i.e. the probability with which that event can be recalled in the presence of the cue. This is the gross valence; in foresight of information theory (Cover and Thomas, 2001), Tulving also introduced the reduced valence of cue X by Y as the probability that the target can be recalled to cue X and not to cue Y, and the common valence of two cues, X and Y, as the probability that the target can be retrieved by cue X as well as by cue Y. (In modern parlance the term is mutual information.) The Tulving-Watkins test is built around the simple operations of presenting a word, the event or the episode to be remembered in this test, and probing it with two successive cues, repeated many times in order to estimate the valences of the cues.
Simple information-theoretic considerations, termed reduction method by Tulving and Watkins, yield estimations for valences of retrieval cues from the data points from the experimental test. We compare the observations on human subjects from the original papers to similar observations on LLMs (see Section Methods) and discuss some implications for the understanding of remembering in LLMs.
Results
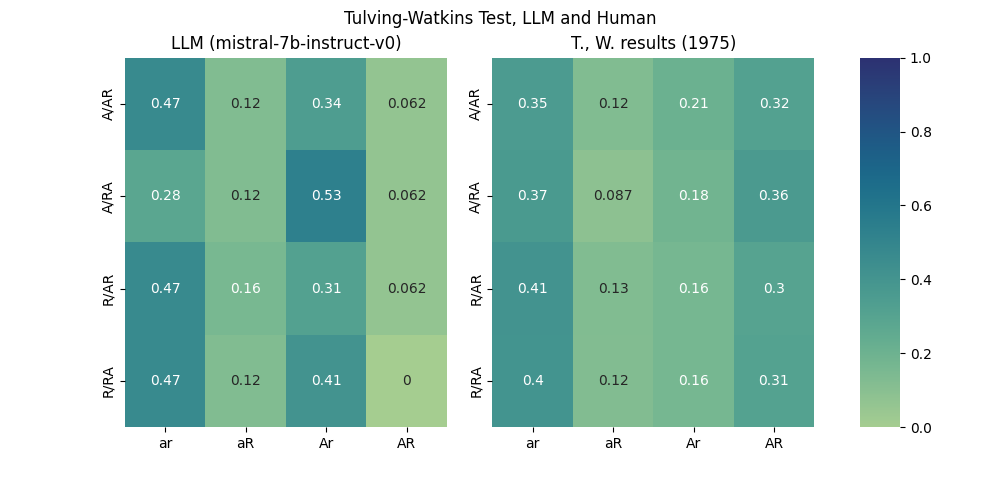
An overview of memory performance of the mistral-7b-instruct-v0 LLM is presented in Figure 2 (left) for direct comparison with results discussed in (Tulving and Watkins, 1975) (right). A first remark is that overall the probability of failure to pass both recall tests is higher in LLMs than in human subjects, except for the A/RA signature–associated word context in encoding, followed by rhyming then associative retrieval cues in recall. The rhyming cue seems more distracting for the human subject than for the LLM, or rather as distracting as the other way around in human subjects’ responses.
The second remark is that LLMs are much better than human subjects at remembering through associative retrieval cues rather than through rhyming cues (comparing third column from the left in each table). Human subjects display a more balanced performance remembering both through associative and rhyming retrieval cues (comparing the third and fourth columns in each table).
Finally, human subjects perform best on associative encoding, recalling the target word on both orders of retrieval cues with probabilities .32 and .36, about one in three. LLMs, in contrast, while similarly slightly better on associative encoding are much better at associative recall, with probability .53, passing over half of the tests.
| Retrieval | R | R | ||||||
|---|---|---|---|---|---|---|---|---|
| Cue | + | - | Total | + | - | Total | ||
| A | + | 0.01 | 0.47 | 0.49 | 0.33 | 0.19 | 0.52 | |
| - | 0.10 | 0.42 | 0.12 | 0.36 | ||||
| Total | 0.11 | 0,45 | ||||||
| Cue | + | - | Total | + | - | Total | ||
| A | + | 0.02 | 0.36 | 0.38 | 0.27 | 0.16 | 0.43 | |
| - | 0.12 | 0.50 | 0.16 | 0.41 | ||||
| Total | 0.14 | 0,43 |
A preliminary remark is appropriate as we look into Table 1. The reduction method used by Tulving and Watkins assumes that in successive retrievals a cue that does not elicit a recall leaves the memory trace unchanged. In the Methods section this is captured by equation \eqref{org168229a} which must hold. While this is the case, up to some negligible noise or sampling variability in the human performance reported in the original paper, this is no longer the case in the measured LLM memory performance. We apply nonetheless the original reduction method, even though the measured discrepancy in the results shown in Table 1 is .08 and .17, respectively for associative and rhyming encodings, both values not negligible in our opinion (.06, however, for aggregate encodings, which is equal to the discrepancy found in the results published in (Tulving and Watkins, 1975)).
The apparent distinction between human and LLM performances is that LLM recall, although slightly inferior in associative cue retrieval, falls comparatively far behind in rhyming cue retrievals. Failure to recall any of the target words is higher in LLMs, by .08 and .09 for respective encodings, and successful recall on both encodings is almost null for LLMs while, in contrast, it is the highest probable result in humans when recall occurs.
Discussion
Although LLM neural networks, and particularly their Transformer architecture, were not specifically designed for memory tasks as other networks may have been (Hochreiter and Schmidhueber, 1997, Jason Weston et al., 2014), the results above and those in (Chauvet, 2024) show their episodic memory performance not to be insignificant. As simple-minded at it may sound, the idea of describing memory traces with gross, common and reduced valences of two or more retrieval cues was proved successful in exploring human memory performance (Desgranges and Eustache, 2011). This principle also proves its value at outlining what a memory trace looks like in a Transformer-based LLM – if only because (i) it provides an internally consistent set of statements about what the memory trace is and what its properties are, and (ii) a set of objectively specified rules for translating experimental observations into theoretical terms in both human and LLM subjects.
Note that this outline neither demands nor assumes any kind of real existence of some thing stored in the memory system (whether human or LLM). The valence-theoretical memory trace is a hypothetical construct that serves to organize a large list of relations between different questions directed at the system and the output of the same system. Similarly, a large subset of the relations between words, which constitute much of the knowledge encoded in pretrained LLMs, are well-approximated by a single linear transformation (Evan Hernandez et al., 2023). In the Tulving Machine SPI Model, this relational knowledge plays the role of the Semantic Memory, linked to familiarity responses.
Peculiarities, of course, emerge from the comparison of valences observed in human and in the LLM subjects (see Results). Further studies (Adlam et al., 2009) investigated the relation between episodic and semantic memory, for which the results above hint at a different nature in humans and in LLMs. This line of research work convincingly demonstrated that “patients with semantic dementia, who have an incontrovertible deficit in semantic memory, are reported to show good day-to-day memory for recent events; but experimental evidence on their anterograde episodic memory/new learning is somewhat sparse and does not always tell a consistent story.” Obviously the situation is somewhat inverted in the case of LLM: namely, many of the recalls fail because the response involves an extra-list word, strongly associated to the retrieval cue in semantic memory whatever the cue’s valence is relative to the target. Relations in the pretrained semantic memory of LLMs often seem to overwhelm and supersede locally memorized relations in a chat.
In this respect, the famous case of patient K.C. (R. Shayna Rosenbaum et al., 2005) is evidence that “[K.C’s] ability to make use of knowledge and experiences from the time before his accident shows a sharp dissociation between semantic and episodic memory. A good deal of his general knowledge of the world, including knowledge about himself, is preserved, but he is incapable of recollecting any personally experienced events. In displaying such ”episodic amnesia,“ which encompasses an entire lifetime of personal experiences, K.C. differs from many other amnesic cases.” While superficially similar in the poor LLM results at recollection (and specifically so in non associative encodings circumstances) compared to human memory tasks performance, patient K.C.’s predicament is much stronger.
Where, then, do Transformers sit between semantic dementia and episodic amnesia?
Elaborations of the episodic buffer (Baddeley, 2000) posited “a limited capacity system that provides temporary storage of information held in a multimodal code, which is capable of binding information from the subsidiary systems, and from long-term memory, into a unitary episodic representation. Conscious awareness is assumed to be the principal mode of retrieval from the buffer.” The relevance of Baddeley’s proposal to LLM understanding may be read in the following statement: “The suggestion that the episodic buffer forms the crucial interface between memory and conscious awareness places it at the centre of the highly active line of research into the role of phenomenological factors in memory and cognition. Tulving, for example, defines his concept of episodic memory explicitly in terms of its associated phenomenological experience of remembering. Although not all theorists would wish to place phenomenological experience so centrally, there is increasing evidence to suggest that conscious monitoring of the evidence supporting an apparent memory plays a crucial role in separating accurate recall from false memory, confabulation and delusion.” The role played by conscious memory (Conway et al., 1996) and its hypothesized neural substrates, chiefly the hippocampus and the medial temporal lobes (Jaffard, 2011, Yonelinas et al., 2023), are evidently without equivalent in LLM’s artificial neural networks. The Tulving Machine, however, if considered as a model may be subjected to a proper treatment (Smolensky, 1988), at least in spirit at this preliminary stage (Smolensky et al., 2022). The central thesis of the original 1988 paper is that connectionist models are subsymbolic. Now, under the hypothesis, put forward by Tulving himself (Tulving, 1983) as an overall pretheoretical framework, of the Tulving Machine model of memory being thus a symbolic representation, together with the assumption of the encoding specificity, could we consider Transformer-based LLMs as submemory?
From the results in the previous section, the episodic buffer, a term that generally refers to the complex node of functional relationship between episodic, working and semantic memory, operates in the “submemory Transformer” differently than in the human counterpart. The experience designs derived from the Tulving Machine, however, proved their usefulness as appropriate tools to investigate memory traces in LLMs. Unraveling episodic buffer complexities is likely to provide a fruitful and potentially tractable research program. Nonetheless, going back to 1988 at the height of the previous cycle (Chauvet, 2018), Searle’s question (Searle, 1990) (adapted) “To what reality do the Transformer models correspond?” still begs for an answer.
Methods
We transpose the successive probes and reduction methods described in (Tulving and Watkins, 1975) for testing LLM “subjects”. Individual experiments are programmed as Python scripts interacting with LLMs through the LLM CLI utility and library (Willison, 2023) (Python 3.11.8 on Windows 10). Results presented and discussed in this paper were obtained with mistral-7b-instruct-v0 (Albert Q. Jiang et al., 2023). (Results with smaller models, e.g. orca-mini-3b (Pankaj Mathur, 2023), were not significant or reliable enough.)
Sixteen unrelated to-be-remembered words were selected from the Oxford English Dictionary. Each of them was presented to a LLM in a prompt asking for an associated word and a rhyming word. While the LLM responses were correct for associated words, it was not so for rhyming words. Rhyme cue words were then obtained using the CMU Pronouncing Directory (Carnegie Mellon Speech Group, ). This selection was repeated to produce a list of sixteen target words, each with two associated words and two rhyming words to be used as cues in the test.
In a chat, the LLM was presented with the target words, each accompanied with a context word, the input cue. One half of the context words were associatively (A) related to the target word, while the other half were words that rhymed (R) with the target word. The two types of input cues, A and R, defined the two encoding conditions of the experiment. In this presentation, the context was stated explicitly either as “is associated to” or as “rhymes with”. The firts prompt in the chat instructed the LLM to memorize the list and prepare for a cue-recall test.
In these tests, implemented as question prompts in the same chat, each target word was probed twice successively, once with an associative cue–different from the one used in the memorization of the list– and once with a rhyming cue–also different from the one in the given context of the initial list. To accommodate various token-sized contexts, the 16 words were tested in four batches of four chats, rather than in one longer 16-word chat.
Of each of the subset of 4 targets, two had been encoded with respect to an associative context word and two with respect to a rhyming word. One word in each of these pair of targets was first probed with a rhyming cue and then with an associative cue (RA), while for the other word, the order of cues was reversed (AR). Therefore each target word within the list represented a unique set of experimental conditions.
The results of these observations, i.e. the LLM producing or not the target word, were collected into data matrices which were then treated by the reduction method.
In the Tulving Model, the pattern of cue valences (say for cue X and Y) shown in Table 2 describes the trace of the target word.
| Second cue Y | |||
|---|---|---|---|
| First cue X | + | - | Total |
| + | XY | Xy | X |
| - | xY | xy | x |
| Total | Y | y |
The table collects the notional valences defined by Tulving and Watkins. The gross valence of cue X is simply X = XY + Xy, where the convention is to use lower-case letter for negative recall and upper-case letter for positive recall of the target word. The gross valence of cue Y is similarly read as Y = XY + xY. The reduced valences are shown in each individual cell, e.g. the valence of cue X reduced by cue Y is Xy. Finally the common valence of cue X and cue Y is in the upper-left cell: XY.
The quantitative description of memory traces is however a bit more complicated, as the valences of the two cues may depend on the order in which they are actually presented. The order of presentation YX, for instance, would yield another data matrix shaped as Table 2. And this is to be expected if the first cue changed, or re-encoded, the trace, since the two cues would practically be applied to different re-encoded traces. Tulving and Watkins developed the reduction method to compute (in an information theory compliant way) a proper trace matrix from the two XY and YX data matrices.
The reduction method, for the details of which we refer to the original paper (Tulving and Watkins, 1975), relies on the basic assumption that presenting a retrieval cue might cause a re-encoding of of the target trace only if the cue is successful in effecting a recall; a cue that does not elicit a recall of the target item is assumed to leave the trace intact. This assumption, in relation to LLMs, is further discussed in the previous sections. Note that the assumption entails that xy and yx are equal, barring noise and measurement errors, since none of the cues, whichever the order of presentation, elicited a recall of the target word. Provided the assumption, cells in the trace matrix are defined by the following elementary calculations:
\begin{equation} \label{org1c7d022} x_t y_t = (xy + yx)/2 \end{equation} \begin{equation} \label{org704237f} X_t = X(1 - x_t y_t)/(1 - xy) \end{equation} \begin{equation} \label{org1132e11} Y_t = Y(1 - x_t y_t)/(1 - yx) \end{equation} \begin{equation} \label{org4daed7d} x_t Y_t = xY(1 - x_t y_t)/(1 - xy) \end{equation} \begin{equation} \label{orga0779e4} X_t y_t = yX(1 - x_t y_t)/(1 - yx) \end{equation}under the assumption above, captured by the following equation:
\begin{equation} \label{org168229a} X_t Y_t + X_t y_t + x_t Y_t = Y_t X_t + Y_t x_t + y_t X_t \end{equation}with the same upper-case/lower-case notation for the trace matrix gross valences, \(X_t\) and \(Y_t\), reduced valences, \(X_t y_t\) and \(x_t Y_t\), and common valences, \(X_t Y_t\), irrespective of the order.
| Cue Y | |||
|---|---|---|---|
| Cue X | + | - | Total |
| + | \(X_t Y_t\) (subtract from total) | \(X_t y_t\) (from Eqn. \eqref{orga0779e4}) | \(X_t\) (from Eqn. \eqref{org704237f}) |
| - | \(x_t Y_t\) (from Eqn. \eqref{org4daed7d}) | \(x_t y_t\) (from Eqn. \eqref{org1c7d022}) | \(x_t\) (add row) |
| Total | \(Y_t\) (from Eqn. \eqref{org1132e11}) | \(y_t\) (add column) |
References
Chauvet, Jean-Marie (2024). Memory GAPS: Would LLMs pass the Tulving Test? :https://arxiv.org/abs/2402.16505.
Chauvet, Jean-Marie (2018). The 30-Year Cycle In The AI Debate.
Carnegie Mellon Speech Group (). The CMU Pronouncing Dictionary.
Adlam, A.-L.R.; Patterson, K.; Hodges, J.R. (2009). “I remember it as if it were yesterday”: Memory for recent events in patients with semantic dementia, Elsevier BV :http://dx.doi.org/10.1016/j.neuropsychologia.2009.01.029.
Albert Q. Jiang; Alexandre Sablayrolles, Arthur Mensch; Chris Bamford; Devendra Singh Chaplot; Diego de las Casas; Florian Bressand; Gianna Lengyel; Guillaume Lample; Lucile Saulnier; Lélio Renard Lavaud; Marie-Anne Lachaux; Pierre Stock; Teven Le Scao, Thibaut Lavril; Thomas Wang; Timothée Lacroix; William El Sayed (2023). Mistral 7B.
Baddeley, Alan (2000). The episodic buffer: a new component of working memory?, Elsevier BV :http://dx.doi.org/10.1016/s1364-6613(00)01538-2.
Conway, Martin A.; Collins, Alan F.; Gathercole, Susan E.; Anderson, Stephen J. (1996). Recollections of true and false autobiographical memories., American Psychological Association (APA) :http://dx.doi.org/10.1037/0096-3445.125.1.69.
Cover, Thomas M.; Thomas, Joy A. (2001). Elements of Information Theory, Wiley :http://dx.doi.org/10.1002/0471200611.
Desgranges, Béatrice; Eustache, Francis (2011). Les conceptions de la mémoire déclarative d’Endel Tulving et leurs conséquences actuelles, John Libbey Eurotext :http://dx.doi.org/10.1684/nrp.2011.0169.
Endel Tulving (1995). Organization of Memory: Quo Vadis, MIT Press.
Eustache, Francis; Desgranges, B\’eatrice (2008). MNESIS: towards the integration of current multisystem models of memory, Springer Science and Business Media LLC.
Evan Hernandez; Arnab Sen Sharma; Tal Haklay; Kevin Meng; Martin Wattenberg; Jacob Andreas; Yonatan Belinkov; David Bau (2023). Linearity of Relation Decoding in Transformer Language Models.
Hochreiter, Sepp; Schmidhueber, Jurgen (1997). Long Short-Term Memory, Neural Comput. :https://doi.org/10.1162/neco.1997.9.8.1735.
Jaffard, Robert (2011). La mémoire déclarative et le modèle de Squire, John Libbey Eurotext :http://dx.doi.org/10.1684/nrp.2011.0174.
Jason Weston; Sumit Chopra; Antoine Bordes (2014). Memory Networks.
Pankaj Mathur (2023). An explain tuned OpenLLaMA-3b model on custom wizardlm, alpaca, and dolly datasets, GitHub, HuggingFace.
R. Shayna Rosenbaum; Stefan Köhler; Daniel L. Schacter; Morris Moscovitch; Robyn Westmacott; Sandra E. Black; Fuqiang Gao; Endel Tulving (2005). The case of K.C.: contributions of a memory-impaired person to memory theory, Neuropsychologia :https://www.sciencedirect.com/science/article/pii/S0028393204002696.
Searle, John R. (1990). Models and reality, Behavioral and Brain Sciences.
Smolensky, Paul (1988). On the proper treatment of connectionism, Cambridge University Press.
Smolensky, Paul; McCoy, R. Thomas; Fernandez, Roland; Goldrick, Matthew; Gao, Jianfeng (2022). Neurocompositional computing in human and machine intelligence: A tutorial, Microsoft :https://www.microsoft.com/en-us/research/publication/neurocompositional-computing-in-human-and-machine-intelligence-a-tutorial/.
Tulving, Endel (1983). Elements of Episodic Memory, Oxford University Press.
Tulving, Endel; Watkins, Michael J. (1975). Structure Of Memory Traces, American Psychological Association (APA) :http://dx.doi.org/10.1037/h0076782.
Willison, Simon (2023). LLM.
Yonelinas, Andrew; Hawkins, Chris; Abovian, Ani; Aly, Mariam (2023). The Role of Recollection, Familiarity, and the Hippocampus in Episodic and Working Memory, Center for Open Science :http://dx.doi.org/10.31234/osf.io/5gwz9.
Author information
Jean-Marie Chauvet is a co-founder of Neuron Data and served as its CTO (1985-2000). He no longer maintains any affiliation.
J.-M. C. performed all analyses and wrote the manuscript as an independent researcher.
Ethics declarations
The author declare no competing interests.
Electronic supplementary material
Data Availability
Results of the Tulving-Watkins Tests analysed in the paper are publicly available in the repository: https://github.com/CRTandKDU/TulvingTest/tree/main/tulving/output
Code Availability
Python scripts for the Tulving Test and tabulation of their results are publicly available in the repository: https://github.com/CRTandKDU/TulvingTest/tree/main/tulving

The content of this page by CRT_and_KDU is licensed under a Creative Commons Attribution-Attribution-ShareAlike 4.0 International.